Category: Artificial Intelligence - Page 10

Education Projects with Vibe Coding: Teaching Software Architecture Through AI-Powered Examples
Vibe coding is transforming how software architecture is taught by letting students build real apps with AI, focusing on design over syntax. Early results show faster learning, deeper understanding, and broader access to programming education.

v0, Firebase Studio, and AI Studio: How Cloud Platforms Support Vibe Coding
Firebase Studio, v0, and AI Studio are transforming how developers build apps using natural language and AI. Learn how vibe coding works, which tool to use for what, and why this is the future of development.

Talent Strategy for Generative AI: How to Hire, Upskill, and Build AI Communities That Work
Learn how to build a real generative AI talent strategy in 2025: hire for hybrid skills, upskill effectively with hands-on learning, and create communities where AI knowledge actually sticks.
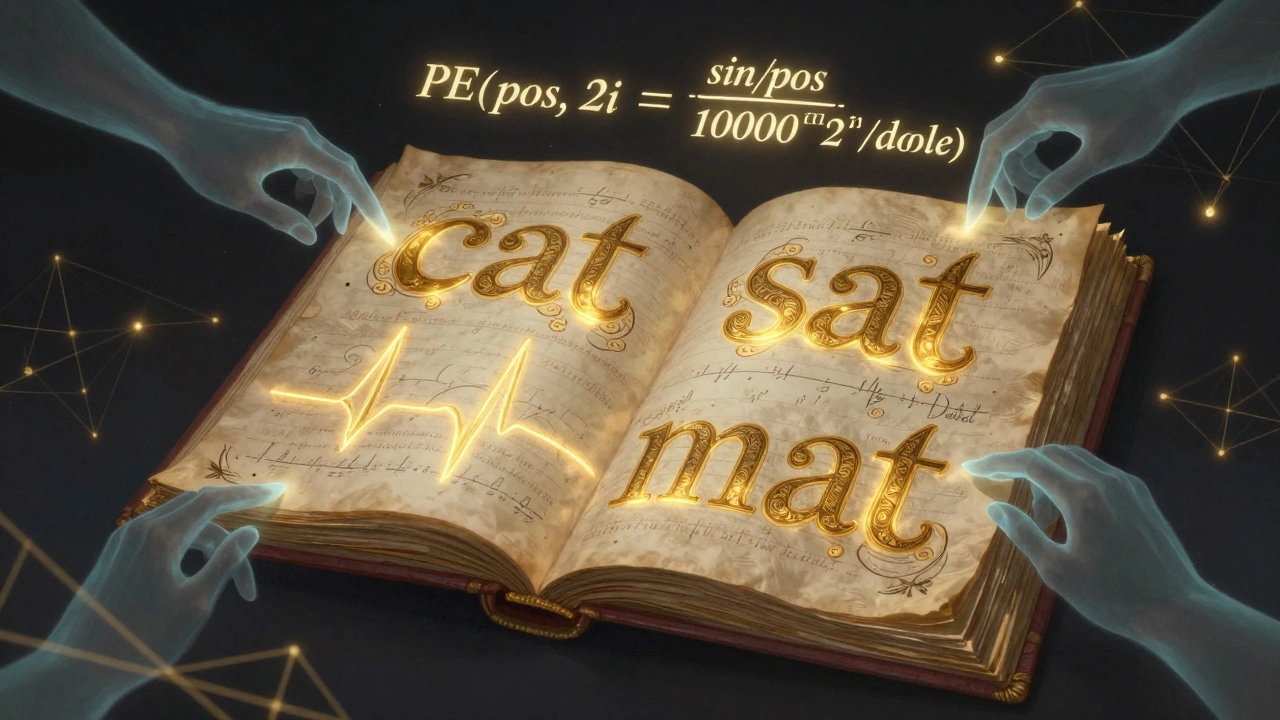
Positional Encoding in Transformers: Sinusoidal vs Learned for Large Language Models
Sinusoidal and learned positional encodings were the original ways transformers handled word order. Today, they're outdated. RoPE and ALiBi dominate modern LLMs with far better long-context performance. Here's what you need to know.

Benchmarking Vibe Coding Tool Output Quality Across Frameworks
Vibe coding tools are transforming how code is written, but not all AI-generated code is reliable. This article breaks down the latest benchmarks, top-performing models like GPT-5.2, security risks, and what it really takes to use them effectively in 2025.

Model Distillation for Generative AI: Smaller Models with Big Capabilities
Model distillation lets you shrink large AI models into smaller, faster versions that keep 90%+ of their power. Learn how it works, where it shines, and why it’s becoming the standard for enterprise AI.

Vision-First vs Text-First Pretraining: Which Path Leads to Better Multimodal LLMs?
Text-first and vision-first pretraining are two paths to building multimodal AI. Text-first dominates industry use for its speed and compatibility. Vision-first leads in complex visual tasks but is harder to deploy. The future belongs to hybrids that blend both.

Safety in Multimodal Generative AI: How Content Filters Block Harmful Images and Audio
Multimodal AI can generate images and audio from text-but it also risks producing harmful content. Learn how safety filters work, which providers lead in blocking dangerous outputs, and why hidden attacks in images are the biggest threat today.

How to Validate a SaaS Idea with Vibe Coding for Under $200
Learn how to validate a SaaS idea using AI-powered vibe coding tools for under $200 in 2025. No coding skills needed. Real examples, real costs, real results.

Code Execution as a Tool for Large Language Model Agents: How AI Systems Run Code to Solve Real Problems
Code execution lets LLM agents run the code they write, turning them from assistants into active problem-solvers. Learn how GitHub Copilot, CodeWhisperer, and Codey use sandboxing to safely execute code-and why security remains the biggest challenge.

Batched Generation in LLM Serving: How Request Scheduling Shapes Output Speed and Quality
Batched generation in LLM serving boosts efficiency by processing multiple requests at once. How those requests are scheduled determines speed, fairness, and cost. Learn how continuous batching, PagedAttention, and smart scheduling impact output performance.

Few-Shot vs Fine-Tuned Generative AI: How Product Teams Should Choose
Product teams need to choose between few-shot learning and fine-tuning for generative AI. This guide breaks down when to use each based on data, cost, complexity, and speed - with real-world examples and clear decision criteria.




