You type a few lines of natural language into an AI tool. Within seconds, you have a working function, a database schema, or even a full frontend component. It feels like magic. But that speed comes with a hidden cost: the AI doesn’t know your organization’s security policies. It doesn’t care about GDPR, HIPAA, or your internal data handling standards. This is where vibe coding governance becomes non-negotiable.
Vibe coding-the practice of using large language models to generate code from natural language prompts-is transforming software development. However, without strict data classification rules for inputs and outputs, you are essentially handing over your most sensitive logic to a model trained on public internet data. The result? Code that works but leaks secrets, bypasses authentication, or mishandles personally identifiable information (PII). To use these tools safely in production, you need a structured framework that treats AI-generated code with the same scrutiny as human-written code.
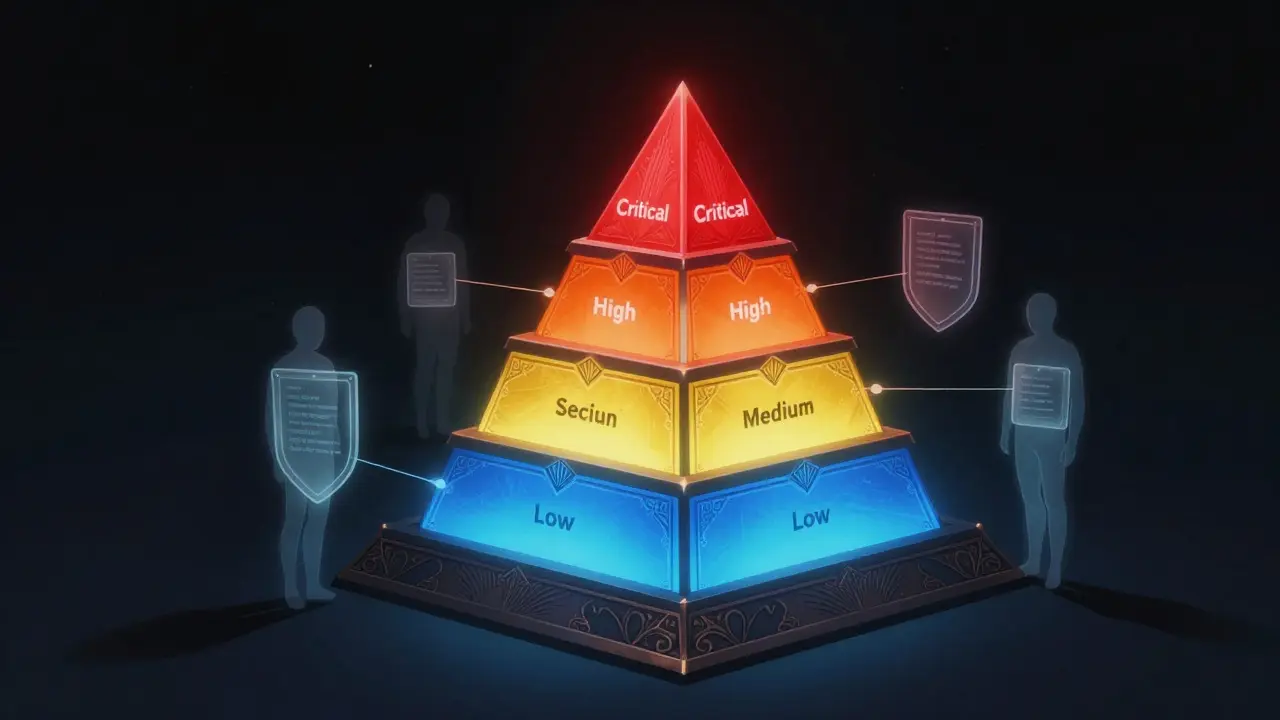
The Four-Tier Data Classification Taxonomy
Before you can secure vibe-coded outputs, you must classify what you are building. Not all code is created equal. A login page carries significantly more risk than a footer widget. The Vibe Coding Framework establishes a risk-stratified system with four distinct tiers: Critical, High, Medium, and Low. This taxonomy dictates how strictly you verify the generated code.
| Classification Tier | Component Examples | Verification Level | Required Actions |
|---|---|---|---|
| Critical | Financial data, Authentication mechanisms, PII handlers | Level 3 (Highest) | Security specialist review, comprehensive documentation, manual audit |
| High | Data processing pipelines, External integration points | Level 2 | Automated security scanning, peer review |
| Medium | Standard functionality, Internal UI components | Level 2 | Automated scanning protocols |
| Low | Internal tools, Non-critical static pages | Level 1 | Ongoing compliance monitoring only |
This tiered approach ensures you don’t waste resources auditing low-risk components while neglecting high-stakes areas. For instance, a Critical classification triggers Level 3 verification. This means no code touches production without a security specialist’s sign-off. In contrast, Low classification components might only need automated checks. The key is matching the oversight intensity to the potential impact of a breach.
Handling PII and Sensitive Data in Prompts
One of the biggest pitfalls in vibe coding is feeding sensitive data directly into the prompt. When you ask an AI to "generate a regex pattern for US Social Security Numbers," you are exposing the structure of that data to the model. While the model itself may not store your specific query forever, the generated code often contains hardcoded patterns or logic that mishandles Personally Identifiable Information (PII).
Research by David Jayatillake highlights a subtle but dangerous flaw in how data classification tools handle PII detection in AI contexts. The technical task of writing regex rules for PII is easy. The hard part is sequencing. If your data classification pipeline applies exclusion logic after tagging operations, you create a window where sensitive data is exposed unnecessarily. In vibe coding, this translates to generating code that tags data as sensitive too late in the process, leaving it vulnerable during transmission or temporary storage.
To mitigate this, enforce a rule: never include actual PII examples in your prompts. Use synthetic, clearly labeled placeholders instead. Furthermore, ensure that any auto-tagging logic in your generated applications runs before data enters bulk processing stages. This prevents the "exclusion after tagging" vulnerability that renders many security functions ineffective.
Environment Variables and Secret Management
If there is one universal rule for vibe coding outputs, it is this: never trust the AI to manage secrets. The Cloud Security Alliance’s Secure Vibe Coding Guide explicitly warns against hardcoding credentials. AI models are designed to be helpful, not secure. They will happily embed database passwords, API keys, and JWT tokens directly into the source code if you don’t explicitly instruct them otherwise.
Your data classification rules must mandate that all sensitive configuration values-database URLs, usernames, passwords, and API keys-are stored in environment variables. When prompting the AI, specify: "Use environment variables for all database connections." Then, verify the output. Even with clear instructions, models sometimes slip up, especially when generating complex boilerplate.
This distinction is vital between development and production environments. Vibe coding tools often generate code with overly permissive defaults suitable for local testing but disastrous for live systems. A connection string that works on your laptop might expose your entire user base if pushed to production without proper variable abstraction.
CORS and Row-Level Security Misconfigurations
Beyond secrets, vibe coding tools frequently misconfigure access controls. Two common failure points are Cross-Origin Resource Sharing (CORS) and Row-Level Security (RLS).
For CORS, AI tools often default to wildcard settings (`*`), which allow any website to make requests to your API. This is convenient for development but catastrophic for security. Your governance framework must require manual verification of CORS configurations, restricting access to only trusted domains. The AI’s default assumption is openness; your job is to enforce restriction.
Row-Level Security is even trickier, particularly in platforms like Supabase. Research by Escape Technologies found that default RLS policies in vibe-coded apps are often left in permissive "development mode." This means users can potentially see each other’s data. Proper RLS implementation requires explicit policies ensuring users can only access their own records. The AI might generate the table structure correctly but fail to implement the nuanced permission logic required for multi-tenant security. You must treat RLS policies as Critical classification components, requiring manual review and testing.
The Exposed Secrets Problem
The consequences of ignoring these classification rules are stark. A study by Escape Technologies analyzed thousands of applications built with vibe coding platforms like Lovable, Base44, and Bolt.new. They discovered over 2,000 vulnerabilities. A significant portion involved exposed secrets.
The researchers used a multi-stage verification process to distinguish real credentials from placeholders. They found that vibe-coded applications frequently exposed Supabase service role keys. These keys grant elevated privileges, effectively giving attackers admin access to your database. This isn’t just a theoretical risk; it’s a systematic failure of current AI tools to classify which data elements require protection.
The lesson is clear: AI tools do not natively enforce data classification rules. They generate code based on probability, not policy. You cannot rely on the tool to keep your secrets safe. You must implement external security scanning and post-generation remediation processes. Treat every output as potentially compromised until proven otherwise.

Building a Governance Framework for System Owners
So, how do you operationalize this? System owners must extend enterprise security requirements into the vibe coding workflow. This starts with prompt templates. Instead of ad-hoc prompts, use standardized templates that include privacy verification criteria. For example, a template for generating a user profile endpoint should explicitly state: "Implement input validation, use parameterized queries, and store credentials in environment variables."
Next, integrate verification checklists. The Guide for System Owners recommends embedding enterprise knowledge management systems into the development process. This ensures that data classification standards remain synchronized across organizational systems. When a new regulation like GDPR updates its definitions of PII, your prompt templates and verification checklists must update accordingly.
Finally, adopt risk-based verification. You can’t manually review every line of AI-generated code. Focus your efforts on Critical and High classification components. Use automated scanning for Medium and Low tiers. This graduated oversight mechanism balances security with productivity, acknowledging that comprehensive review of all outputs is operationally infeasible.
Conclusion: Security is a Post-Generation Process
Vibe coding is powerful, but it is not autonomous. The AI is a junior developer who moves fast but lacks judgment. Your role as a governance leader is to provide the guardrails. By implementing strict data classification rules for inputs and outputs, you transform vibe coding from a security liability into a scalable asset. Remember: the code is only as secure as the process that verifies it.
What is vibe coding?
Vibe coding is an AI-assisted programming approach where users describe software requirements in natural language, and large language models generate the corresponding code implementations. It speeds up development but introduces unique security challenges related to data classification and secret management.
Why are data classification rules important for AI-generated code?
AI models do not inherently understand organizational security policies or regulatory compliance requirements. Without explicit data classification rules, they may generate code that exposes sensitive data, uses insecure default configurations, or fails to properly handle PII, leading to significant security vulnerabilities.
How should I handle API keys in vibe-coded applications?
Never hardcode API keys in the source code. Always use environment variables to store sensitive credentials. Explicitly instruct the AI to use environment variables for all authentication mechanisms and verify that the generated code adheres to this practice before deployment.
What are the common security risks in vibe coding outputs?
Common risks include exposed secrets (like database passwords and API keys), misconfigured CORS settings allowing unrestricted cross-origin access, permissive Row-Level Security (RLS) policies, and improper handling of Personally Identifiable Information (PII). These issues often stem from the AI’s tendency to prioritize functionality over security.
Can AI tools automatically enforce data classification rules?
Currently, no. Most vibe coding tools do not natively implement comprehensive data classification rules that enforce organizational security policies. Human oversight, automated scanning, and post-generation verification processes are essential to close the gap between AI capabilities and security requirements.